
Wie man einen Datensatz für die visuelle Qualitätskontrolle mit KI erstellt (Teil 1)
- deevio

- 3. Jan. 2022
- 3 Min. Lesezeit
Motivation
Wir bei deevio wissen, dass ein guter Datensatz der Schlüssel zum Erfolg eines automatisierten Bildverarbeitungssystems ist. Umgekehrt ist es sehr schwierig oder sogar unmöglich, ein genaues KI-Modell zu trainieren, wenn der Datensatz ungenau oder inkonsistent gelabelt ist. Unabhängig davon, welche hochmodernen Deep-Learning-Architekturen oder Modelltrainingstechniken verwendet werden.
Dieser Beitrag soll helfen, einen qualitativ hochwertigen Datensatz zu erstellen und zu labeln, indem häufige Fehler vermieden und bewährte Verfahren aus all unseren bisherigen Projekten befolgt werden.
Vorbereitung des Projekts
Das Geschäftsziel im Auge behalten
Das/die Hauptziel(e) eines Inspektionssystems müssen von Anfang an klar sein. Wollen Sie die Kosten senken, die Anzahl der übersehenen Fehler reduzieren, die Anzahl der fälschlicherweise zurückgewiesenen Produkte verringern, die Produktionsgeschwindigkeit erhöhen usw.? Soll das System vollständig automatisiert sein? Oder wird ein Mensch an dem Prozess beteiligt sein?
Die Antworten auf diese Fragen zu kennen und sie mit unseren Data Scientists zu diskutieren, ist in jeder Phase des Projekts hilfreich, angefangen bei der Datenerfassung. Außerdem hilft es bei der Festlegung einer geeigneten Metrik zur Bewertung des Modells und beim entsprechendem Training.
Erst den Umfang einschränken, dann bei Erfolg vergrößern
Wenn Sie Ihr Ziel vor Augen haben, kann der Umfang auf einen begrenzten, aber für dieses Ziel relevanten Bereich reduziert werden, um eine erste Aussage über die Machbarkeit des Projektes zu bekommen. Es könnte am Anfang des Projekts zum Beispiel nur eine Produktart, nur eine Fehlerart oder nur eine Perspektive betrachtet werden, für die dann zum Start bis zu 100 (aber nicht viel weniger) statt mehreren 100 Bildern aufgenommen und genutzt werden. Wenn das Ziel beispielsweise darin besteht, die durch fehlerhafte Ausschussteile verursachten Kosten zu senken, wählen Sie einen einzigen Produkttyp, bei dem diese Kosten am höchsten sind.
Ein begrenzter Umfang reicht also aus, um abzuschätzen, ob das Problem prinzipiell lösbar ist und es kostet weniger Zeit und Mühe, die Daten zu erfassen und zu labeln. Außerdem ist es einfacher, einen kleineren Datensatz neu zu erfassen und/oder neu zu labeln, falls im Laufe der Zeit Fehler entdeckt werden.
Entscheiden Sie, ob eine Fehlerlokalisierung erforderlich ist
Es kann ausreichen, nur zu wissen, ob ein Produkt defekt ist oder nicht. In diesem Fall reicht ein einziges Label pro Bild aus, und das ist ein Problem der Bildklassifizierung.
Wenn die genaue Position eines Defekts auf einem Bild erforderlich ist, gibt es nur wenige Möglichkeiten. Wenn es ausreicht, einen Rahmen um einen Defekt zu erhalten, handelt es sich um ein Problem der Objekterkennung. Wenn es notwendig ist, die Position der Defekte auf Pixel-Ebene zu sehen, handelt es sich um ein semantisches Segmentierungsproblem (wenn die Trennung benachbarter Defekte desselben Typs nicht erforderlich ist) oder um ein Instance Segmentierungsproblem (wenn es erforderlich ist, benachbarte Defektinstanzen zu trennen). Eine Illustration dieser Unterschiede finden Sie unten.
Lokalisierte Labels sind aufwändiger zu erstellen, aber selbst in Fällen, in denen es ausreicht, ein Label pro Bild zu erhalten, kann die Segmentierung ein Modell erklärbarer machen, und zwar als Alternative zu den Methoden der erklärbaren KI wie Integrated Gradients, die versuchen, die Entscheidung eines Klassifizierungsmodells zu erklären.

Entscheiden Sie, ob eine Unterscheidung der Fehler erforderlich ist
Es ist wichtig zu entscheiden, ob es notwendig ist, einfach zwischen fehlerhaften (niO) und guten Produkten (iO) zu unterscheiden oder verschiedene Arten von Fehlern wie Kratzer oder Porositäten zu erkennen und zu unterscheiden. Darüber hinaus kann es für einige Anwendungen sinnvoll sein, eine Abstufung der Defekte vorzunehmen, z.B. kleine/mittlere/große Kratzer.
Ähnlich wie bei der Lokalisierung kann eine detaillierte Kennzeichnung der Defekte dazu beitragen, die Erklärbarkeit oder Genauigkeit des Modells zu verbessern. Auch wenn das Wissen, ob ein Produkt fehlerhaft ist oder nicht ausreicht, um eine Maßnahme zu ergreifen, z. B. bei einer automatisierten Produktionslinie.





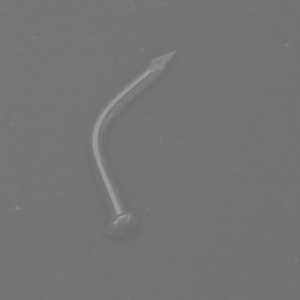

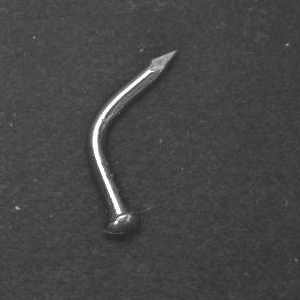
Das Finden eines geeigneten Bildaufnahmesystems
Ein gutes Bildverarbeitungssystem mit richtig gewählter Konfiguration ist auch beim Einsatz von KI erforderlich, um einen hochwertigen Datensatz zu erfassen. Die Bilder müssen in Bezug auf Helligkeit, Kontrast, Auflösung und anderen Eigenschaften gut genug sein, um zwischen fehlerhaften und guten Bildern zu unterscheiden und um verschiedene Fehlertypen zu erkennen.
Um sicherzustellen, dass die Ergebnisse einer Machbarkeitsstudie oder eines Proof-of-Concepts in der Produktion reproduziert werden können, muss die Konfiguration eines Bildverarbeitungssystems gleich bleiben, einschließlich der Umgebung, in der es eingesetzt wird. Ein System, das in einem dunklen Raum gut funktioniert hat, funktioniert möglicherweise nicht mehr, wenn es in einen sonnigen Raum gebracht wird (ohne zusätzliches Tuning).
Deevio kann Ihnen bei der Entwicklung eines geeigneten Bildverarbeitungssystems helfen und Bilder Ihrer Produkte für Sie erstellen.
Verwenden Sie nach Möglichkeit ein verlustfreies Bildformat
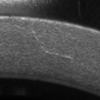

Datensätze für die visuelle Inspektion haben oft sehr kleine Defekte, wie z. B. Kratzer, die nur wenige Pixel groß sein können. In solchen Fällen ist es besser, Bilder in einem verlustfreien Format wie PNG oder BMP zu speichern als in einem verlustbehafteten Format wie JPEG, es sei denn, die Speicherkapazität oder Bandbreite wird zum Problem.


Kommentare